第1章:基础知识
Hive解决的问题
用户从一个现有的基于传统关系型数据库和结构化查询语句的基础架构转移到Hadoop上,即使对于经验丰富的Java开发工程师来说,将这些常见的数据运算对应到底层的MapReduce Java API也是令人畏缩的。Hive可以帮助用户来做这些苦活,这样用户就可以集中精力关注于查询本身了。
Hive的特点
Hive不是一个完整的数据库。
Hive不支持记录级别的更新、插入或者删除操作。但是用户可以通过查询生产新表或者将查询结果导入到文件中。
Hive查询延时比较严重。
Hive不支持事务。
Hive组成模块
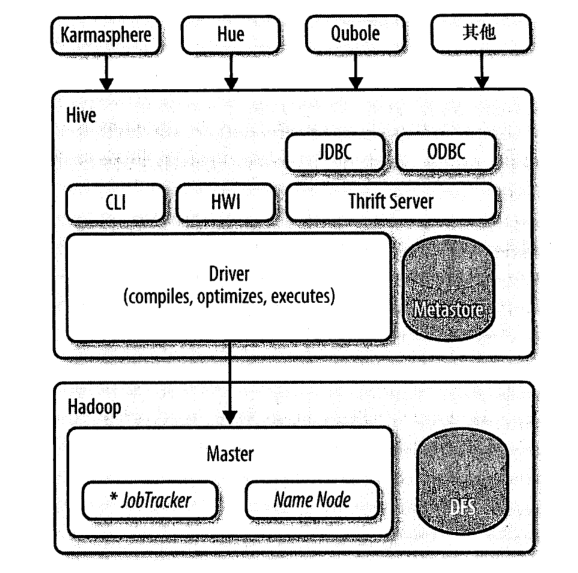
命令/查询进入Driver ——> Driver对输入进行解析编译,对需求的计算进行优化 ——> 启动多个MapReduce任务(job)
- 当需要启动MR任务时,Hive本身不生成MR算法程序。而是通过一个表示“job执行计划”的XML文件-驱动执行内置的、原生的Mapper和Reduce模块。
- Hive通过和JobTracker通信来初始化MR任务(job),而不必部署在JobTracker所在的管理节点上执行。
在大型集群中,通常会有网关机专门用于部署像Hive这样的工具。在这些网关机上可远程和管理节点上的JobTracker通信来执行任务(job)。
通常要处理的数据文件是存储在HDFS中的,而HDFS是由NameNode进行管理的。
- Metastore(元数据存储)是一个独立的关系型数据库(通常是一个Mysql实例),Hive会在其中保存表模式和其他系统元数据。面试必备: 手写wordcount的MapReduce代码!!!
