MapReduce原理
1 mapreduce原理
1.1 mapreduce的主要目的
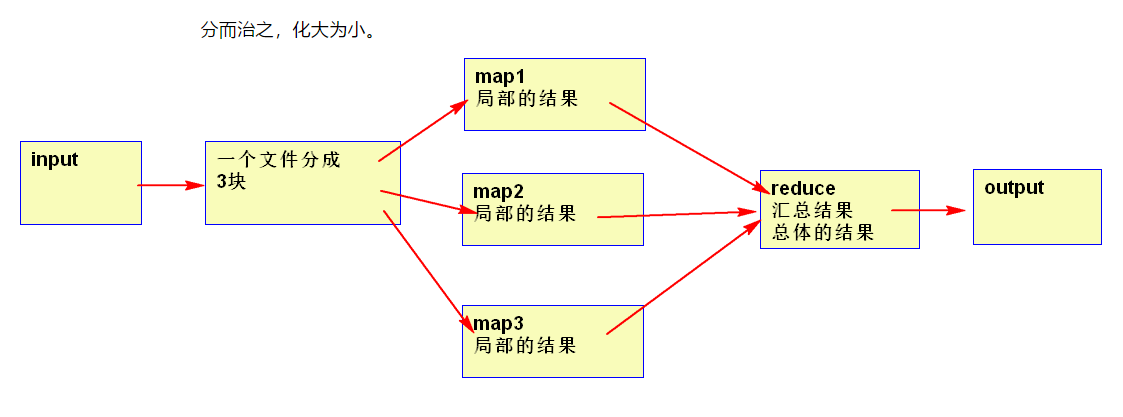
分而治之,化大为小。
1.2 map和reducer阶段分别解决什么样的问题
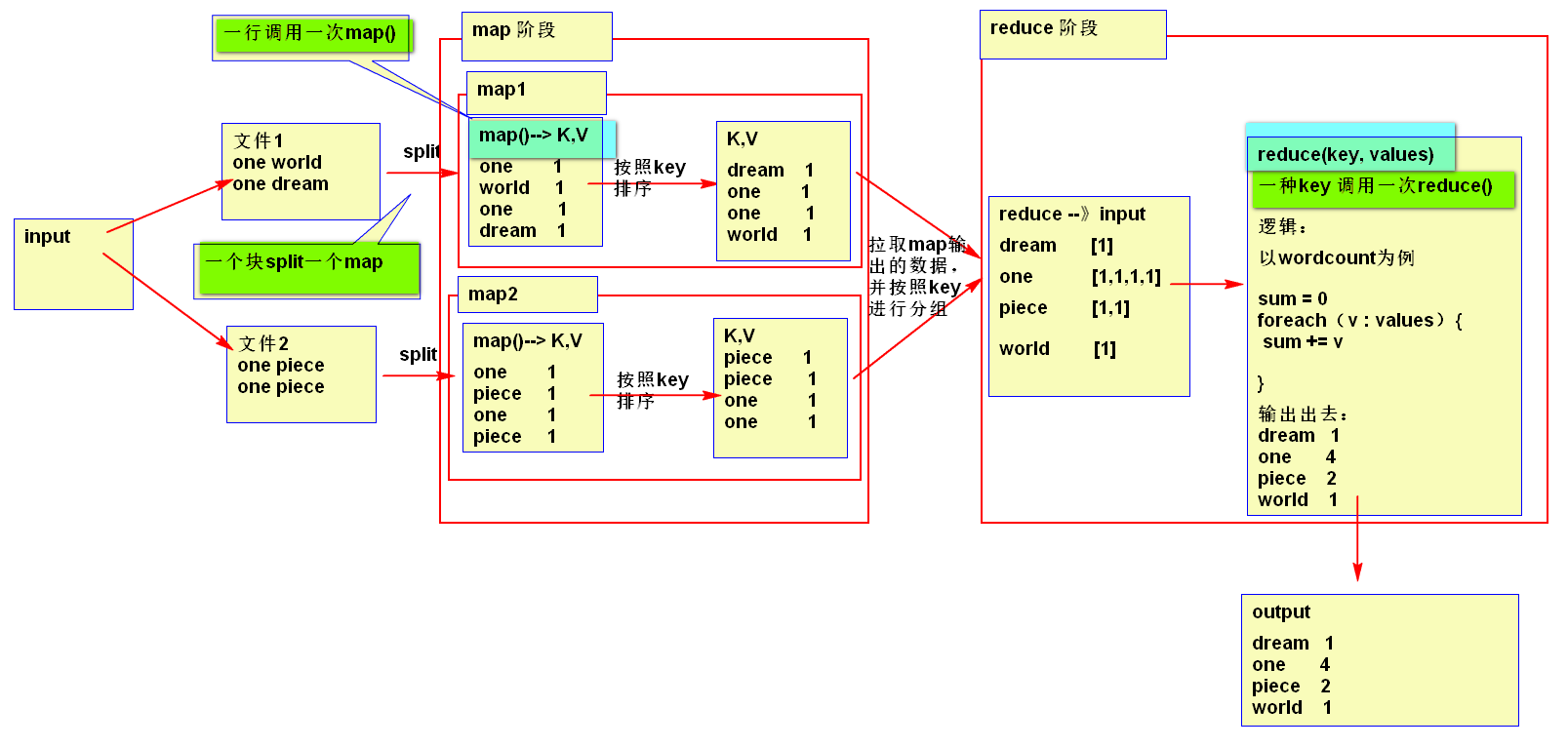
map阶段解决的问题,就是把输入数据变成Key,Value结果,用于reducer的输入
局部有序
reducer 解决的问题的就是按分组进行汇总
全局有序
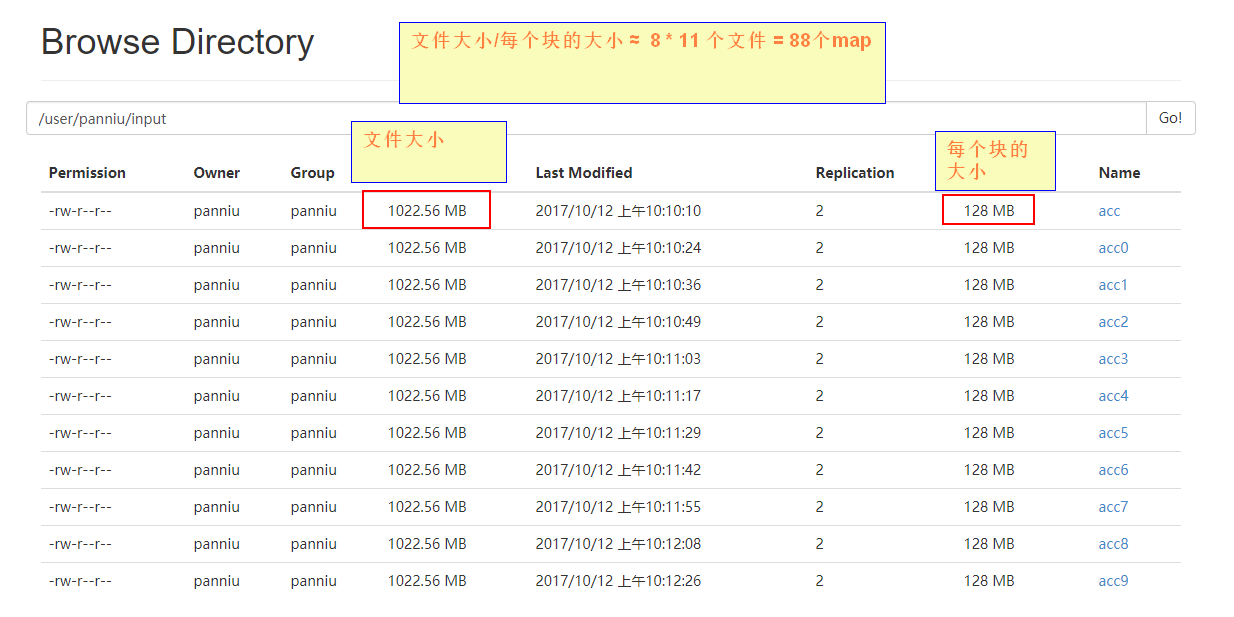
1.3 map任务的输入文件是怎么分割的
inputSplit split默认一个block对应一个split,这个split可以自己实现成对应多个block。


1.4 wordcount中map阶段做了什么
按一个词当key,values按1输出
输出某一个key[1,1,1,1,1,1,1,1,1,1,1,1] key2[1,1,1,1,1,1,1,1,1,1,1,1]
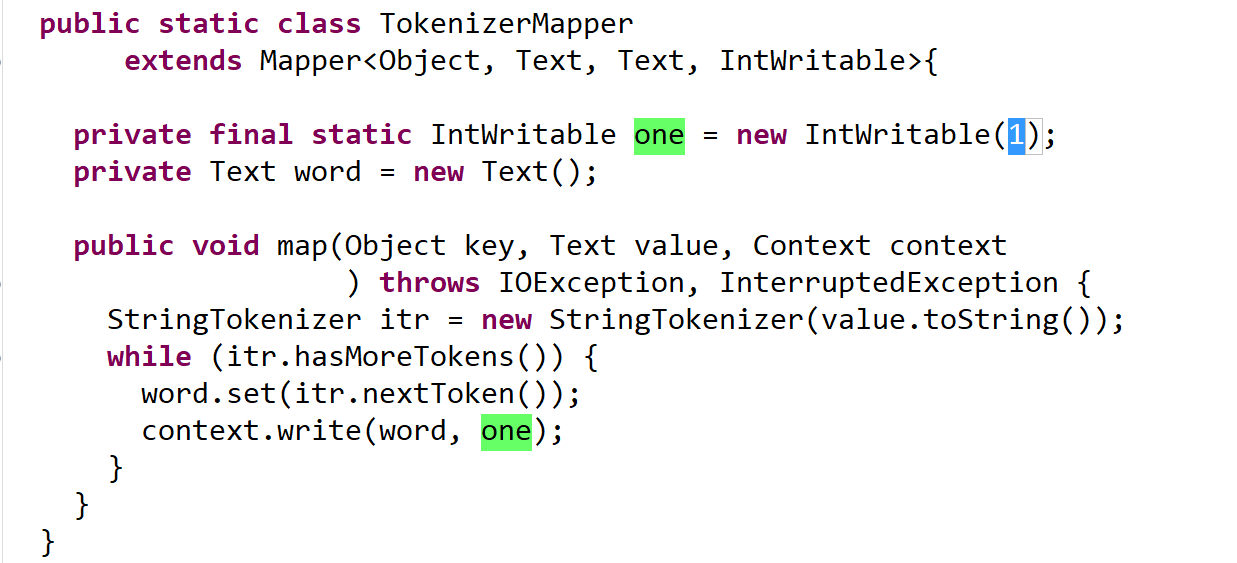
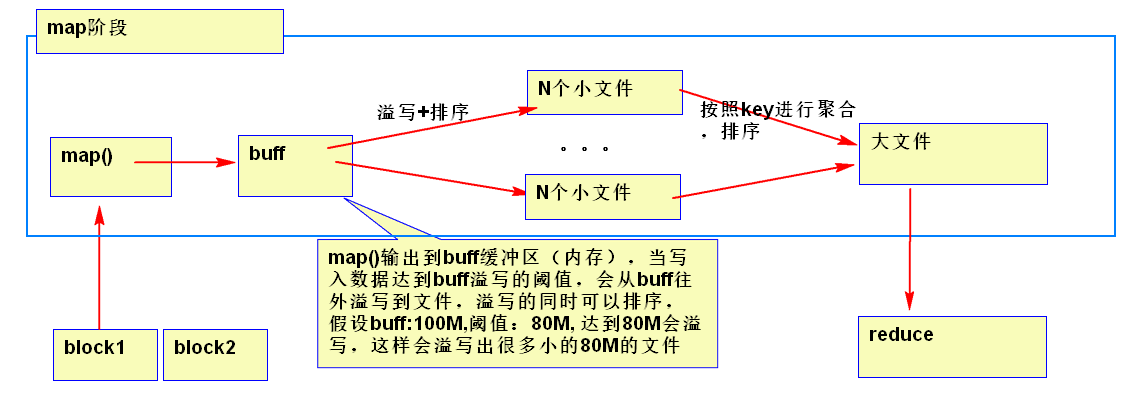
map运行图
一个reduce的情况
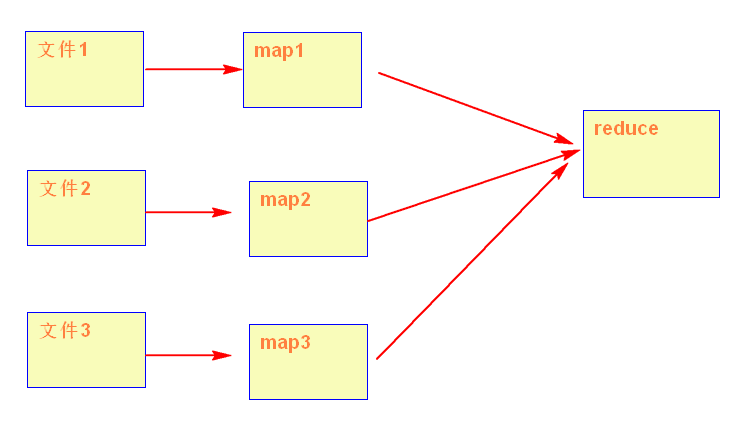
两个reduce情况
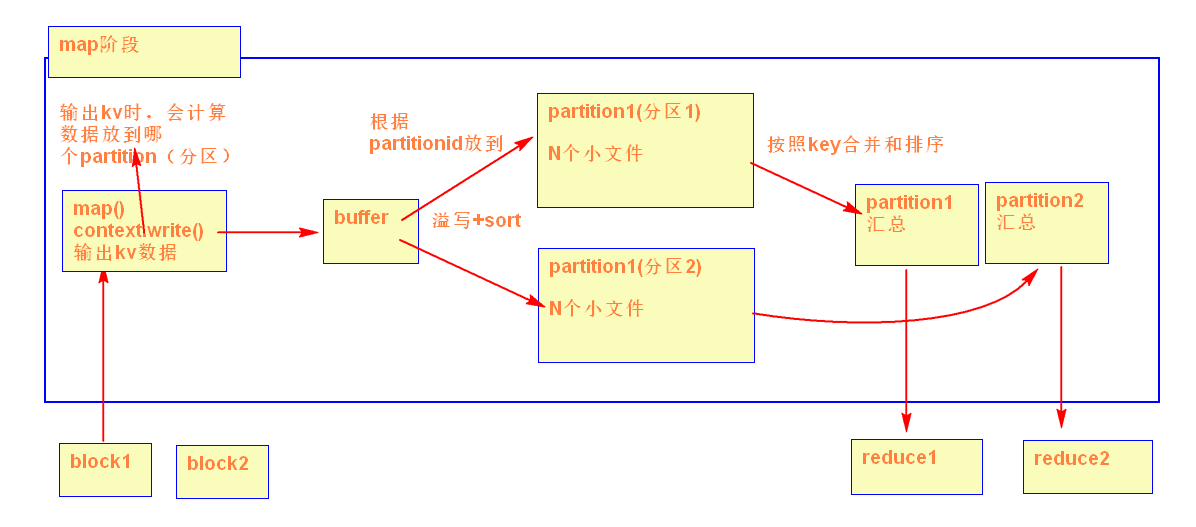
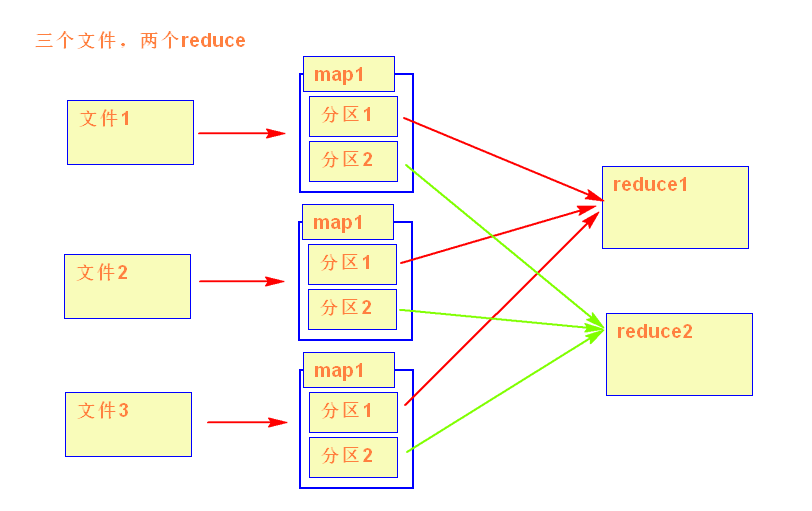
1.5partition的数量是怎么决定的
partition的数量是通过reducer的数量决定的
按照key的hash值来分
假设:reduce数量是2
partitionId = key的hash值% reduce的数量
partitionA = key的hash值尾数是0
partitionB = key的hash值尾数是1
如果reduce数量是3
partitionA = key的hash值尾数是0
partitionB = key的hash值尾数是1
partitionC = key的hash值尾数是2
1.6 reducer是怎么从map拉取计算数据的
一个reduce情况
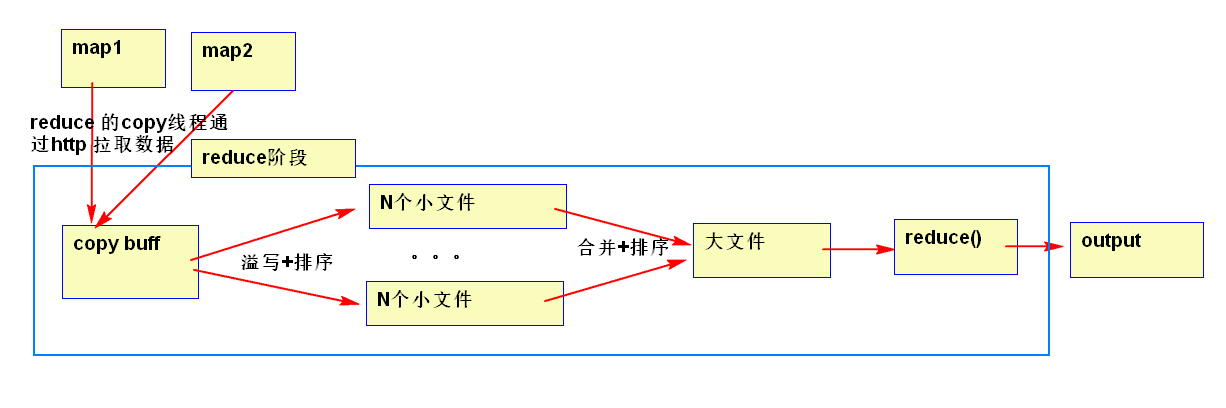
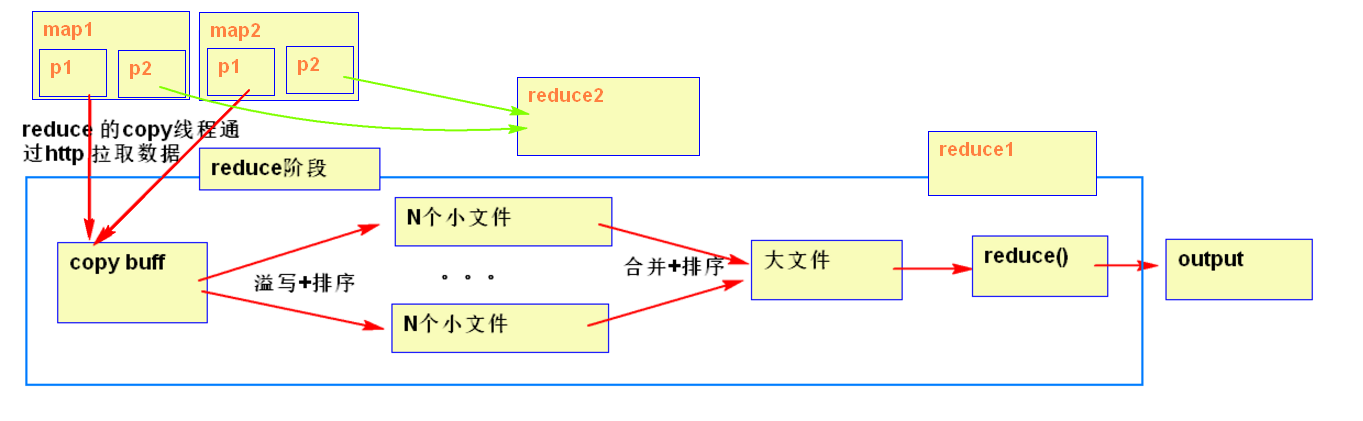
copy merge 占整个reducer运行进度的33%,但可能因为map阶段文件分布不均导致该阶段耗费50-70%的时间。
1.7 怎么减少reducer从map拉取的数据量
1)将map数据进行压缩
2)combiner:在map阶段将球分两个筐,然后分的时候就统计出每筐每种球有多少个,在reduce阶段,直接用每筐每种球的数量这个数据,直接统计每种球的数量。
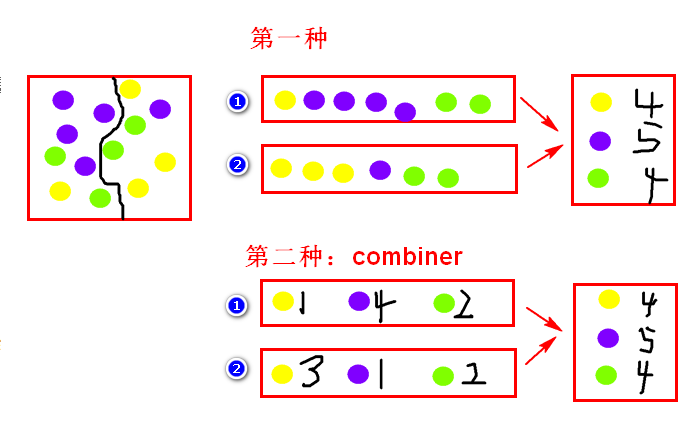

使用combiner可以减少reducer的输入数据量,默认是不提供的因为这个东西不是所有场景都能使用(求top5),需要自己根据需求自定义

1.8 reducer的输入文件是怎么排序的

1.9 wordcount中reducer阶段做了什么
按组累加
假设有4个key a,b,c,d,每个key调用一次reduce方法,统计每个key的数量。

1.10 总结shuffle的整个过程
Shuffle是指从Map 产生输出开始,包括系统执行排序以及传送Map 输出到Reducer 作为输入的过程。
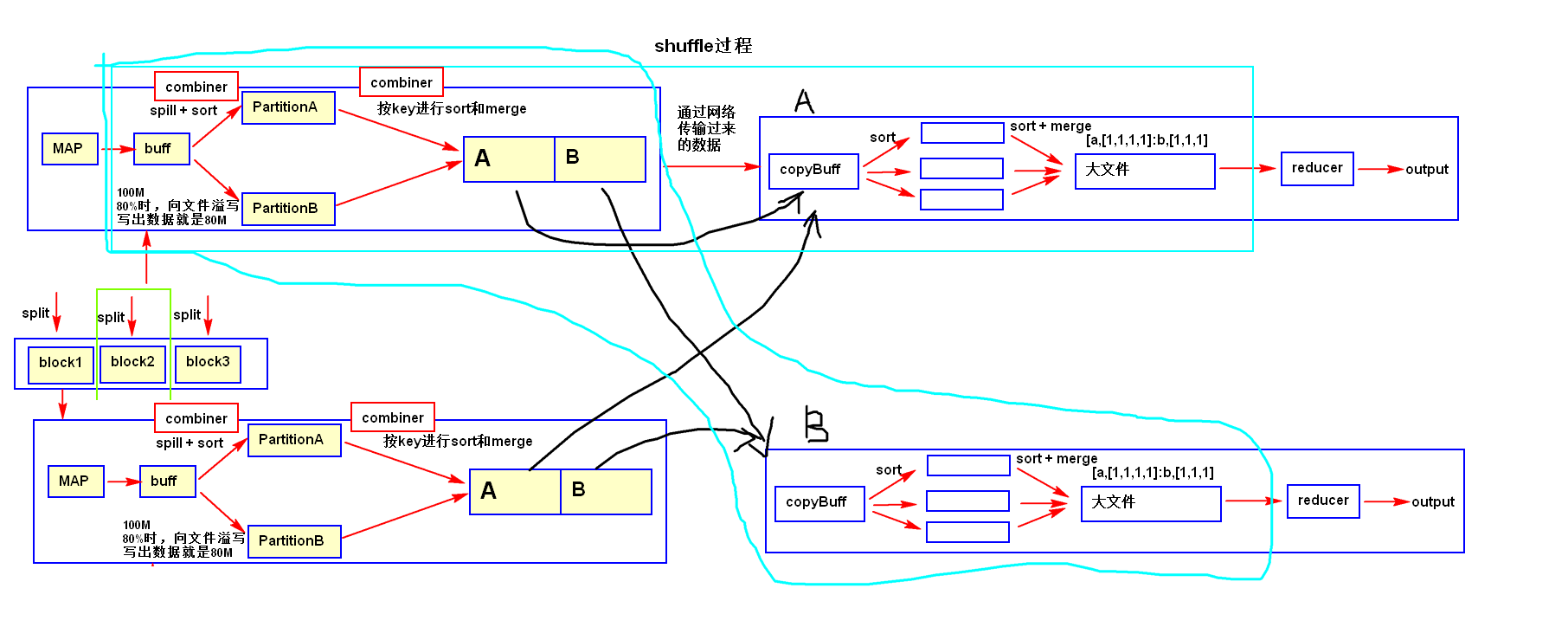
1.11 mapreducer的详细过程
map: inputsplit->read->map->mapbuff->spill->sort–>combiner->partition->sort–>combiner->mergepartitionfile;
reducer: copy->copybuff->merger(内存)->sort->mergerfile(小文件)->sort->sortTotalReducerInputFile(大文件)>reducer->output
2 mapreducer的配置
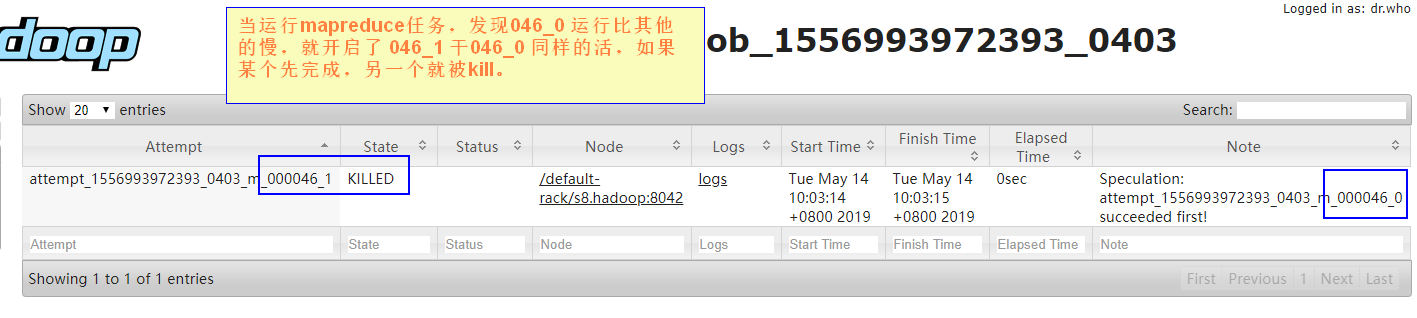
2.1 推测执行
在跑任务的时候,会根据其他节点任务平均完成时间推测哪个任务可能执行会很慢,hadoop会再开一个这样的任务,两个任务谁先跑完用谁的结果,没跑完的任务就被 kill 掉。慢的任务可能该节点有问题或太忙了。
有的时候要把 推测执行 关掉,这个一般是在代码中设置。
2.2 计数器
counters是mapreduce任务里的组件,用于统计。
在工作中需要统计那些不符合实际需求或规则的数据。在数据出现错误的时候,能快速定位到错误的原因。
2.3 配置文件

3 mapreducer可以优化的地方
1)块的大小和文件的数量这个就决定map任务的数量
2)增加map buff缓冲区的大小 mapreduce.task.io.sort.mb
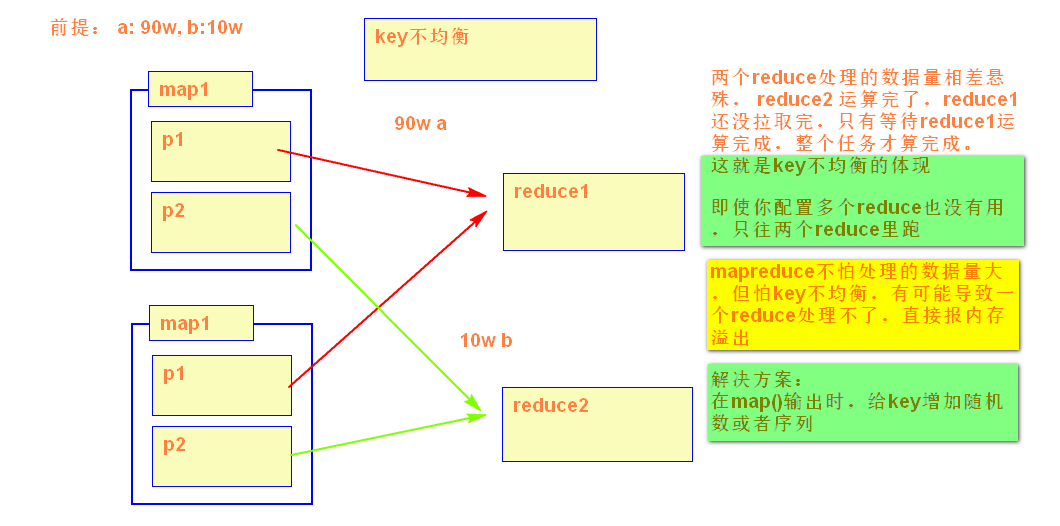
3)map输出的KEY的设计均匀
输出的key+随机数或序列
4)增加reduce的个数
通过-Dmapreduce.job.reduces参数设定
代码设定
5)增加reduce copy buff缓冲区的大小,增加copy线程的线程数
mapreduce.reduce.shuffle.parallelcopies
增加reduce内存
6)减少reduce阶段的数据输入量,在map阶段进行combiner 、map输出时进行数据压缩
7)减少小文件合并大文件的次数
mapreduce.task.io.sort.factor
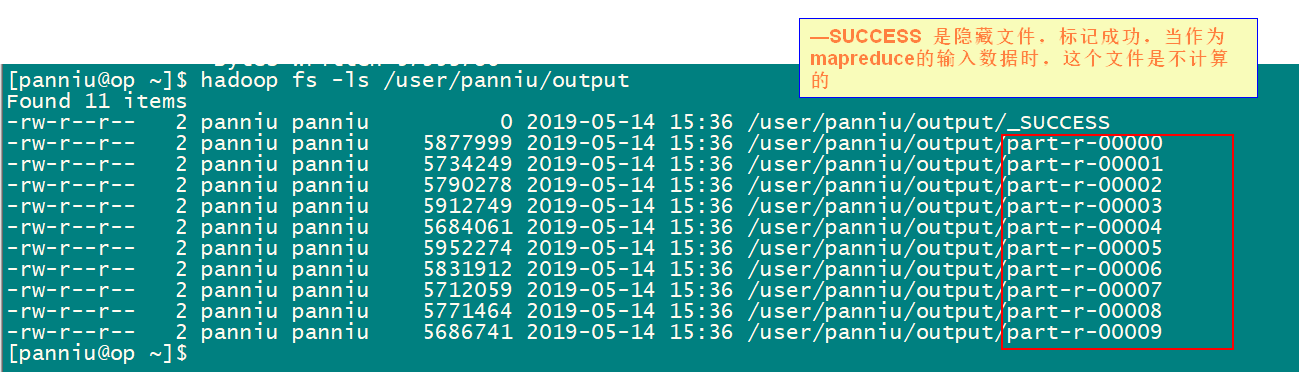
4 如何设置reducer个数
reducer的个数决定最终输出文件的个数,可以通过-Dmapreduce.job.reduces参数设定
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount -Dmapreduce.job.reduces=10 /user/panniu/input /user/panniu/output

生成10个reduce

输出10个文件